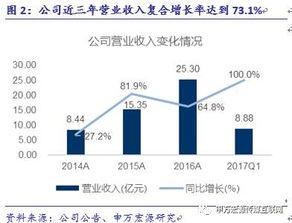
从单机到亿级流量 大型网站系统架构的演进之路
在互联网蓬勃发展的今天,一个成功的网站应用可能从寥寥数人的初创项目,迅速成长为服务亿万用户的技术巨擘。其背后的系统架构,也必须经历一场持续演进、不断蜕变的旅程。这个过程不仅是技术的升级,更是对可扩展性、高可用性、高性能与可维护性核心诉求的深刻回应。本文将系统梳理从单机起步,直至支撑亿级流量的超大型分布式系统的典型架构演进路径。
第一阶段:单机架构——一切的起点
几乎所有大型网站都始于一个简单的想法和一个更简单的实现。在初期,为了快速验证产品(MVP)和节省成本,整个应用通常被部署在一台物理服务器或虚拟机上。应用程序、数据库、文件存储等所有组件都集中于此。
- 技术栈:LAMP(Linux, Apache, MySQL, PHP)或类似的简单组合是典型代表。
- 特点:结构简单,开发部署快捷,成本极低。
- 挑战:存在严重的单点故障风险;性能瓶颈明显,随着用户量增长,CPU、内存、I/O很快会成为瓶颈;扩展性几乎为零,无法通过增加机器来提升能力。
第二阶段:应用与数据分离——首次解耦
当单台服务器的处理能力达到上限,最直接有效的第一步是将应用服务器和数据库服务器分离,部署到不同的机器上。
- 演进:一台服务器专用于运行业务应用程序,另一台(或集群)专门负责数据存储(如MySQL)。两者通过内网连接。
- 价值:实现了初步的解耦,便于针对应用服务器和数据库服务器进行独立的优化和扩展。例如,可以为应用服务器配置更高的CPU,为数据库服务器配置更大的内存和更快的磁盘。
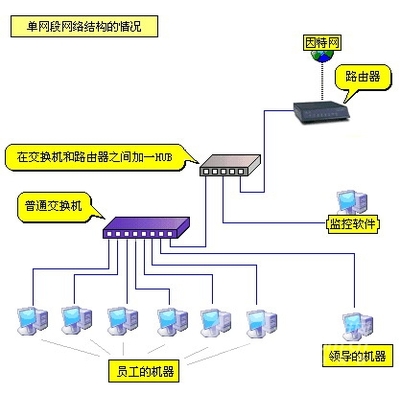
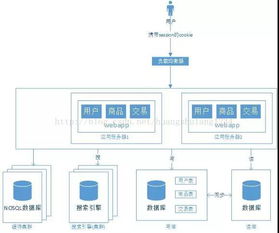
第三阶段:应用服务器集群与负载均衡——横向扩展的开端
应用服务器分离后,其自身很快会成为新的瓶颈。引入负载均衡器(如Nginx, HAProxy)和应用服务器集群是应对之道。
- 架构:用户请求首先到达负载均衡器,由它按照一定策略(如轮询、最小连接数)分发到后方多台应用服务器中的一台。
- 关键点:
- 会话(Session)管理:由于用户请求可能被分发到不同的服务器,需要解决Session共享问题,方案包括Session复制、Session绑定(粘滞会话)或将会话数据集中存储到外部缓存(如Redis)。
- 高可用:负载均衡器本身可能成为单点,需要通过主备或集群方式保障其高可用。
- 价值:通过水平扩展应用服务器,系统处理并发请求的能力得到线性提升,也提高了应用层的可用性。
第四阶段:数据库读写分离与分库分表——突破数据层瓶颈
应用层扩展后,压力会迅速传导至数据库。单一的数据库服务器会面临巨大的读写压力。
- 读写分离:引入主从复制,主库负责写操作,多个从库负责读操作。应用程序通过数据库中间件或框架配置,将读写请求路由到不同的数据库实例。这极大地缓解了读压力。
- 分库分表:当单个数据库实例的存储容量或写性能达到极限时,需要对数据进行水平拆分。
- 垂直分库:按业务模块将不同表拆分到不同的数据库(如用户库、订单库)。
- 水平分表/分库:将同一个表的数据按某种规则(如用户ID哈希、时间范围)分散到多个表或多个数据库中。
- 挑战:引入了分布式事务、跨库查询、全局唯一ID生成等复杂问题。
第五阶段:引入缓存与CDN——加速与减压
大部分网站访问遵循二八定律(80%的请求集中在20%的数据上)。利用缓存技术可以极大提升响应速度并降低后端压力。
- 本地缓存与分布式缓存:
- 首先在应用服务器本地使用Guava Cache等,减少内部计算开销。
- 更重要的是引入Redis、Memcached等分布式缓存集群,存储热点数据(如用户信息、热门商品),避免频繁访问数据库。
- CDN(内容分发网络):对于静态资源(图片、CSS、JS、视频),将其推送到遍布全球的CDN节点。用户访问时,由最近的CDN节点提供服务,极大降低网络延迟,减轻源站带宽压力。
第六阶段:业务拆分与微服务架构——面向复杂性的进化
当系统功能日益庞杂,单体应用会变得臃肿不堪,开发、部署、维护都极其困难。通过业务拆分,将系统解耦为一组小型、自治的服务。
- 演进:从单一应用按业务模块拆分为多个独立的服务,如用户服务、商品服务、订单服务、支付服务等。
- 关键技术:
- 服务治理:服务注册与发现(如Nacos, Consul, Eureka),服务间通信(REST, gRPC),负载均衡,熔断降级(如Hystrix, Sentinel)。
- 统一网关:提供统一的API入口,处理路由、认证、监控、限流等横切关注点。
- 配置中心与链路追踪:实现配置的集中管理和服务调用链路的可视化排查。
- 价值:提升开发效率与系统可维护性,允许不同服务独立部署和扩展,技术栈也可多样化。但同时也带来了分布式系统固有的复杂性,如网络不可靠、数据一致性、运维监控成本增加等。
第七阶段:全面分布式与云原生——亿级流量的基石
为了支撑亿级甚至更高的并发流量和数据处理需求,架构需要进化到全面分布式和云原生阶段。
- 数据层深化:
- 多级缓存架构:客户端缓存 -> CDN -> 反向代理缓存(Nginx) -> 分布式缓存 -> 数据库,形成多级屏障。
- 异构数据存储:根据数据特性选用最合适的存储,如关系型数据库(MySQL/PostgreSQL)、NoSQL(MongoDB, Cassandra)、时序数据库(InfluxDB)、搜索引擎(Elasticsearch)、对象存储(OSS/S3)等。
- 消息队列解耦与削峰:大规模使用Kafka、RocketMQ、Pulsar等消息队列,实现系统间的异步解耦、流量削峰填谷和数据流处理。
- 弹性计算与容器化:采用Docker容器和Kubernetes编排系统,实现服务的快速部署、弹性伸缩和故障自愈,资源利用效率最大化。
- 服务网格(Service Mesh):将服务通信、治理能力(如流量管理、安全、可观测性)下沉到基础设施层(如Istio),使业务代码更专注于逻辑本身。
- 大数据与实时计算:构建独立的大数据平台,使用Flink、Spark等处理海量日志和用户行为数据,进行实时分析与决策。
###
从单机到亿级流量的架构演进,是一个持续应对压力、解决瓶颈、拥抱复杂性的过程。其核心思想始终是:分解、抽象、解耦和冗余。没有一种架构可以一劳永逸,优秀的架构总是与业务共同成长,在不断迭代中寻找成本、效率、性能和复杂度之间的最佳平衡点。对于架构师和开发者而言,理解这一演进历程的内在逻辑,远比掌握某个具体技术更为重要,因为这能帮助我们在面对系统发展的不同阶段时,做出最合适的技术决策。
如若转载,请注明出处:http://www.qqtobe.com/product/56.html
更新时间:2026-06-19 17:26:27